


出品 | 搜狐科技
作者 | 梁昌均
编辑 | 杨锦
在DeepSeek引发市场对“大模型六小龙”的价值质疑半年后,还在坚持做大模型的玩家意图向外界证明自己依然很能打。
从上海的MiniMax到北京的月之暗面,接连推出多款模型和产品,“卷”得厉害。
它们不约而同地把DeepSeek、OpenAI、谷歌等最新最强模型作为对标,并都瞄向了同一个方向——国内外巨头都在布局的智能体(Agent)。
MiniMax和Kimi的久违更新,是对外界质疑的一次回应,也透露出这两家企业仍想继续留在牌桌上的努力,其中MiniMax还爆出计划上市。
严格来讲,“大模型六小龙”的阵营已经崩盘,零一万物和百川智能放弃基座模型训练,咬牙坚持的“四小虎”——智谱、月之暗面、MiniMax和阶跃星辰,还在试图突围。
资本狂飙之后,这些被迅速催熟的独角兽,面临技术和商业的双重挑战。有曾在其中一家独角兽工作过的人士认为,接下来或还会有1-2家掉队。
猛发模型的MiniMax和Kimi
“第一次感觉到大山不是不能翻越”“又跃过了一条河”“越来越强烈地感受是AI的价值可以开始被经济衡量”……
MiniMax最近发布周的每次更新,创始人&CEO闫俊杰总会发出不少感悟,而引发他“大山不是不能翻越”的点是——MiniMax首款开源推理模型M1。
根据基准评测,这款参数达4560亿的模型性能接近海外最领先模型,部分任务超过DeepSeek、阿里、OpenAI、谷歌等最新最强的开闭源模型,尤其是在软件工程、长上下文、工具使用等复杂生产力场景中优势明显。
在海外权威机构Artificial Analysis最新发布的模型综合能力榜单中,MiniMax M1位列全球开源模型第二名,仅次于DeepSeek-R1-0528,跻身全球第一阵营。
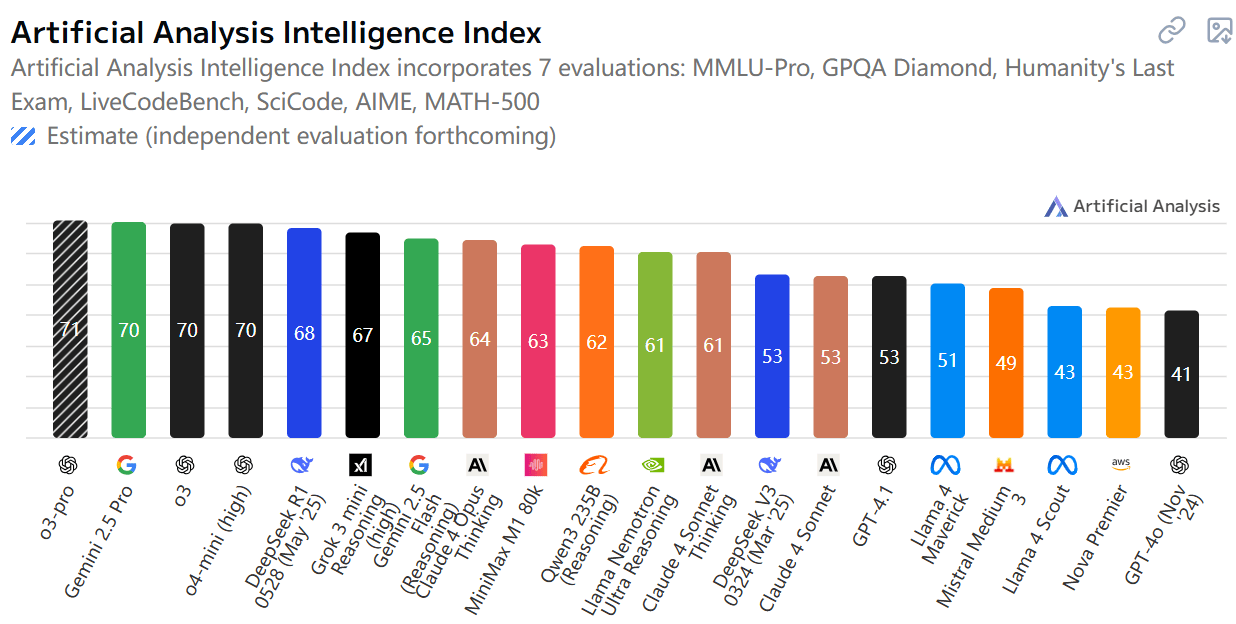
月之暗面同样发布了k系列模型的最新版本Kimi-Researcher,其是基于端到端自主强化学习(end-to-end agentic RL)技术训练的新一代Agent模型。
在覆盖上百个专业领域的高难度基准人类终极考试(HLE)中,Kimi-Researcher取得26.9%的Pass@1分数,超过OpenAI o3、Gemini 2.5 Pro、DeepSeek-R1-0528和Claude 4 Opus。
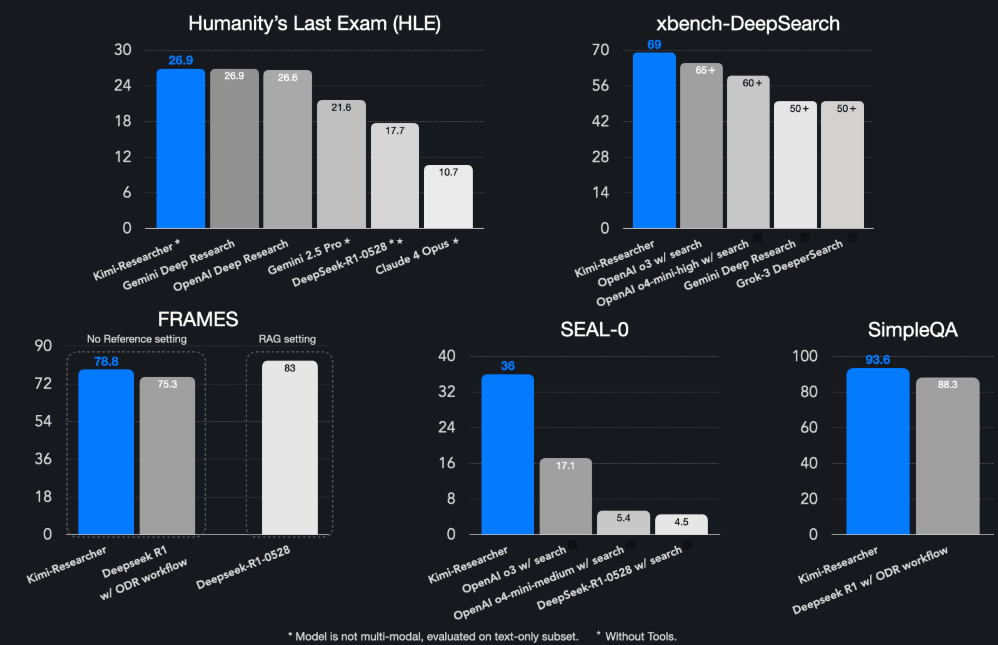
搜狐科技注意到,此次MiniMax和月之暗面在模型层面的突破,背后是对强化学习的重视和算法创新。
M1在进行大规模强化学习时,采用Lightning Attention(闪电注意力)混合架构与创新性的CISPO算法,从而提高了训练效率,扩展了模型性能。
Kimi-Researcher则采用端到端自主强化学习技术,用结果驱动的算法进行训练,摆脱了传统的监督微调和基于规则制或工作流的方式。结果显示,探索规划步骤越多,模型性能就越强。
早在去年o1发布后,月之暗面创始人杨植麟就表示,强化学习是接下来AI的发展方向。随后推出k0-math、k1.5等推理模型,Kimi-Researcher仍是强化学习这条路线的延续。
“真正具备自适应性的通用智能,需要在真实任务的交互与反馈中成长出来。”月之暗面对选择端到端强化学习的技术方式解释到。
同时,新一波的大模型技术竞争也已放弃单纯追求参数、算力规模的传统范式,在推动模型SOTA的过程中,卷成本和效率成为趋势。
DeepSeek此前就将这种高性价比优势充分发布出来,并成为效仿策略。此次的M1借助算法架构创新,强化学习训练过程比DeepSeek-R1 算力消耗更低且效率更高,380万元的成本比预期少了一个数量级。
此外,走向多模态、选择开源也成为越发重要的竞争策略。从最初的语言模型,到多模态,“四小虎”全面追赶竞赛,并均走向开源,这很难说不是受到DeepSeek的影响。
竞逐智能体风口
随着此次MiniMax和Kimi的发布,意味着“四小虎”均涉足Agent领域。
今年被普遍视为Agent元年,搜狐科技了解到,不少AI初创企业自去年改变方向,转做智能体,甚至有企业迅速在B端做到千万级订单。
但面向C端的智能体,还没有哪款产品能牢牢占据用户心智,此前爆火的Manus尚未在国内上线,这意味着仍有机会。
此次月之暗面发布的Kimi-Researcher集模型和智能体于一身,定位于专为深度研究任务而生的智能体,而不是所谓的通用智能体。
一位AI从业者认为,Kimi-researcher带来了一种不同思路的解决方案,其它智能体大多采用Claude的multi-agent(多智能体)方案,通过写很多Workflow(工作流)去做,Kimi则是少有的基于自身模型采取Single-Agent(单智能体)路线。
这与OpenAI基于o3推出的DeepResearch思路相同,而Manus则基于Claude+Qwen模型,核心是多智能体系统。该公司创始人肖弘曾称,Claude是做智能体的最佳模型。
这代表了两种不同的思路。有观点认为,随着模型越来越强大,建立在外部模型之上的智能体的能力将被模型吞噬。但由于不用自研模型,这种方式成为不少创业企业的选择。
“Manus、Genspark、Skywork、Flowith等这些智能体都是多个模型,体验差异感觉不是很大。在审美场景,如前端页面,目前Claude最靠得住。”有大模型企业关注智能体的高管表示。
月之暗面研究员Flood Sung此前认为,各种Agentic Workflow就是各种带Structure的东西,它一定会限制模型能力,没有长期价值,早晚会被模型本身能力取代掉。
因此,月之暗面的做法是让Agent的能力进入到模型本身,并完全依靠强化学习训练,打破传统智能体采取的工作流拼装或监督微调方式存在的固定流程和数据限制,让模型更加灵活通用,并用其自主生成的数据去探索上限。
前述高管认为,模型即Agent这种思路往往是模型厂商的选择,想要开发出所谓的通用智能体,意味着模型本身要够强,意味着这需要投入大量资源去做基模研发。
不过,MiniMax此次发布的适用于长程复杂任务的通用智能体,底层并未采用单一模型。该公司称,这造成了一定的使用成本,正努力研发更高效、成本更低的方案。
搜狐科技了解到,MiniMax Agent和月之暗面不同,采用的是自研+外部模型。“它们还是有很多工程和国外模型的痕迹,但其能力很强,不弱于那几个比较火的Agent。”体验过这款智能体的前述高管表示。
对MiniMax和Kimi来说,通用智能体都是最终目标。目前,Kimi-Researcher还是专注于搜索和推理的智能体,月之暗面希望未来能向着可以解决广泛复杂任务的通用智能体进化。
智谱和阶跃星辰则更早就在发力智能体,但给外界的感觉是更侧重B端落地。智谱已和荣耀、华硕、小鹏、高通、英特尔、三星等等达成智能体合作。
阶跃则与Oppo、吉利、千里科技等企业达成合作。最近,旷视科技创始人印奇入主的千里科技还与该公司联合研发推出智驾模型。
“现在的趋势业内没啥争议,区别只是谁做得更快。”无论是选择自研模型,还是外部模型,选好更能达到目标的技术路线,并更快做出让用户或企业认可的产品,才是关键。
都想要留在牌桌上
MiniMax和月之暗面的系列新品,一定程度上代表了它们对技术和未来方向的探索,更是一次想要留在牌桌上的证明,但仅仅是这些恐怕还不够。
搜狐科技从“四小虎”中的一些员工处获悉,智谱、月之暗面等还在憋大招,“智谱可能还有两次机会,Kimi就这一次了”。
“DeepSeek出来后,这些企业的故事讲不下去了。”有员工认为,像智谱原来觉得自己是国家队,但现在可能这种地位都保不住了。
该人士强调,现在基模仍很关键,如果做出来厉害的模型,市场格局可能又会发生变化。但无论是算力资源还是资金,这几家企业相比DeepSeek都没有太大优势。
同时,现在从各种评价、榜单、用户,以及从API调用趋势来看,DeepSeek还是非常领先,“能与之扳手腕的可能就只有字节,阿里都有点赶不上了”。
自去年以来,大模型就已进入规模定律边际效应递减的瓶颈期。接下来,OpenAI和DeepSeek这两家国内外的领头羊,被视为重要的风向标。
奥特曼最近透露,OpenAI即将推出开源模型,并在今年夏天发布多模态模型GPT-5,DeepSeek何时推出R2也颇受关注。
最新报道称,R2很可能不会在短期内发布,原因在于梁文锋对R2现在的性能还不满意,工程师团队仍在全力优化和打磨,部分原因受到算力影响。这意味着R2仍在谋求远超前代的性能,届时“四小虎”如果停滞不前,压力无疑会更大。
变局之下,“六小龙”变动频繁,今年超十多位高管出走,其中智谱就有4名高管离职,包括负责商业化的张帆、负责战略融资的张阔等,其它企业也出现了联创或副总裁等高管离开的局面。
月之暗面则基本放弃大规模投流策略,产品用户增长和交互有所下滑。该公司还被爆出推出类似于小红书的AI内容社区,从而增加用户黏性,但还未正式上线。
搜狐科技了解到,月之暗面今年重心回归模型研发,下半年会推出新一代多模态大模型,并与智能体结合;商业化则维持现状,其内部资金还能维持三年左右。
坚持多模态且开源的阶跃星辰也有所收敛,角色扮演类产品冒泡鸭停止大范围投入,聚焦Agent方向,发力模型研发,包括强化学习和多模态的理解生成一体化。
MiniMax则宣布品牌拆分,ChatBot产品海螺AI更名MiniMax,海螺AI专指视频生成。随着智能体推出,该公司形成Agent、Talkie/星野、海螺AI为核心的产品矩阵,并继续发力出海。
“AI视频产品的需求已得到初步验证,国内外都会有较大前景,MiniMax做得相对较好,肯定会继续发力。”有AI从业者称。一个例证是,快手的可灵AI今年一季度营收达1.5亿元。
值得关注的是,此次MiniMax发布周期间,还被爆出谋求港股上市。媒体援引知情人士称,其内部有类似想法,但还在初步筹备阶段。
这是继智谱明确开启上市进程之后,国内第二家传出计划上市的AI独角兽,而智谱也被认为是最有希望最早“上岸”的独角兽。
今年以来,智谱从北京、杭州、珠海、成都等地方国资获得20亿元融资,且拿到不少政府订单,从上市加速推动商业化。
“虽然要上市,但我们内部感觉还是很有压力。就算上市也不一定代表安全,能不能保持现有估值是很大挑战,而且很多核心信息都会公开。”有智谱员工对搜狐科技表示,今年智谱也减少了推广投放,重心在于基模和拿订单。
如同此前包括商汤在内的“AI四小龙”一样,上市远非终点。无论是技术方向的变化,还是难以跑通盈利的商业化,依然是这波大模型企业需要应对的挑战。
有曾在“四小虎”工作过的离职人士认为,未来可能还会有1-2家掉队,最后仅剩2-3家存活下来。李开复更激进,认为国内大模型会收敛到DeepSeek、阿里和字节三家企业。
这三家企业基本是行业公认的国内大模型第一梯队,“四小虎”们还得往后站,它们的窗口期也越来越窄。
“商业化干不过豆包等大厂,开源比不过DeepSeek”,是它们面临的尴尬处境。过去以及现在所做的调整,可能会决定他们未来的命运走向。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






